카이제곱 독립성 검증 이론, 공식, 검증절차
카이제곱 필수 지식 (이것만은 알고가자!) 두 범주형(명목 척도) 변수가 서로 독립적인지 확인 기대빈도를 계산해야함 (두 변수가 서로 독립일 때 기대되는 빈도,즉 귀무가설이 참일때 기대되는 빈도를 기대빈도라고 함!) 기대빈도와 관측된 빈도를 비교해서 카이제곱의 통계량을 계산함. 이 값이 클수록 변수 사이에 큰 차이가 있음. 자유도(d.f)는 (행의 수 - 1) × (열의 수 - 1) 카이제곱의 귀무가설(영가설, H0)은 "두 변수아 독립적이다, 즉 연관성이 없다" 임
카이제곱 독립성 검정이란?
카이제곱 독립성 검정(Chi-Square Test of Independence)은 통계학에서 두 범주형 변수 사이에 통계적으로 유의미한 관계가 있는지를 검증하는 방법입니다. 이 검정을 사용하면 두 변수가 서로 독립적인지, 아니면 어떤 연관이 있는지 알 수 있어요.
쉽게 말해, 예를 들어 ‘커피를 마시는 것’과 ‘집중력 향상’이라는 두 가지 사항을 조사한다고 가정해 보겠습니다. 여기서 한 변수는 ‘커피 소비 여부(마신다, 안 마신다)’이고, 다른 변수는 ‘집중력(향상됨, 향상되지 않음)’입니다. 카이제곱 독립성 검정을 통해 이 두 가지가 서로 관련이 있는지, 즉 커피를 마시는 사람들이 집중력이 더 향상되는지 아닌지를 알아볼 수 있습니다.
검정 절차는 대략 다음과 같습니다:
- 데이터 수집: 두 변수에 대한 데이터를 수집하여 교차표(행과 열로 이루어진 표)로 정리합니다.
- 기대 빈도 계산: 두 변수가 서로 독립일 때 기대되는 빈도를 계산합니다. 이는 우리가 관측한 데이터가 아니라, 만약 두 변수가 관계가 없다면 일반적으로 기대할 수 있는 결과입니다.
- 카이제곱 통계량 계산: 관측된 빈도(실제 데이터)와 기대된 빈도(독립일 때의 예상 데이터)의 차이를 이용하여 카이제곱 통계량을 계산합니다. 이 값이 클수록 두 변수 사이에 더 큰 차이가 있다는 것을 의미합니다.
- 결과 해석: 계산된 카이제곱 통계량을 바탕으로, 사전에 정한 유의수준(보통 0.05 또는 5%)과 비교하여 통계적으로 유의미한지 결정합니다. 만약 카이제곱 값이 크다면, 우리는 두 변수가 독립적이라는 가설을 기각하고, 두 변수 사이에는 통계적으로 유의미한 연관이 있다고 결론짓습니다.
간단히 말해서, 카이제곱 독립성 검정은 두 범주형 변수 사이에 연관성이 있는지 확인하는 통계적 방법입니다. 이를 통해 연구자는 두 변수가 서로 독립적인지 아니면 어떤 관계가 있는지를 알 수 있습니다.
기대 빈도(E) 구하는 공식

카이제곱 통계량 공식

카이제곱 공식 논리 1. 차이 측정: 카이제곱 통계량은 관측 빈도(O)와 기대 빈도(E) 사이의 차이를 제곱하여, 이 차이가 우연히 발생했을 가능성을 정량화합니다. 제곱을 하는 이유는 차이의 방향성(양수 또는 음수)이 결과에 영향을 미치지 않도록 하기 위함입니다. 2. 차이의 상대적 중요성: 각 차이를 해당 기대 빈도로 나눔으로써, 차이가 그 카테고리의 기대 빈도에 비해 얼마나 큰지를 측정합니다. 이는 관측치 수가 많은 셀과 적은 셀이 카이제곱 통계량에 동일하게 기여하지 않도록 보정해 줍니다. 3. 독립성 검정: 카이제곱 통계량은 두 변수 사이에 독립성이 있다는 귀무 가설 하에 계산됩니다. 만약 두 변수가 완전히 독립적이라면, 기대 빈도와 관측 빈도 사이에는 큰 차이가 없을 것입니다. 그러나 실제로 유의미한 차이가 관찰되면, 이는 두 변수 사이에 어떤 연관성이 있을 가능성을 시사합니다.
문제로 이해하는 카이제곱 독립성 검증 절차
| 세탁기 담당 마케팅관리자는 가족규모에 따라 구매하는 세탁기의 크기가 다른지 알기 위해 마케팅 조사자와 협의를 통해 주부들을 대상으로 질문을 하고, 교차표는 표로주어진다 같다. 이 자료에 의해 가족규모에 따라 구매하는 세탁기의 크기가 다르다고 할 수 있을까? 유의수준(a)=0.05 |
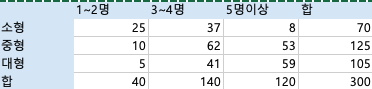
이 마케팅 조사 데이터를 바탕으로, 가족 규모에 따라 구매하는 세탁기의 크기가 다른지를 알아보기 위한 카이제곱 독립성 검정을 진행해 보겠습니다.
1. 가설 설정
- 귀무 가설 (H0): 가족 규모와 세탁기의 크기 사이에는 관련이 없다. (독립적이다)
- 대립 가설 (H1): 가족 규모와 세탁기의 크기 사이에는 관련이 있다. (독립적이지 않다)
2. 기대 빈도 계산 (E)
기대 빈도는 다음 공식으로 계산됩니다:

이제 각 셀에 대한 기대 빈도를 계산해 보겠습니다. 전체 관측치의 수는 300입니다.
예를 들어, 소형 세탁기와 1~2명 가족 규모의 셀에 대한 기대 빈도는:
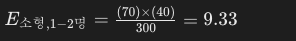
이와 같은 방법으로 모든 셀에 대한 기대 빈도를 계산하겠습니다. Python 코드를 사용하여 모든 셀의 기대 빈도를 계산하고 카이제곱 통계량을 구한 후, 결론을 도출하겠습니다.
기대 빈도와 카이제곱 통계량을 계산한 결과, 각 셀에 대한 기대 빈도는 다음과 같습니다:
- 소형: ([9.33, 32.67, 28.00])
- 중형: ([16.67, 58.33, 50.00])
- 대형: ([14.00, 49.00, 42.00])
3. 카이제곱 통계량 계산
카이제곱 통계량은 각 셀에 대한 관측 빈도와 기대 빈도의 차이를 바탕으로 계산됩니다. 이를 수식으로 표현하면 다음과 같습니다:
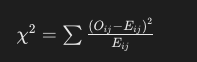
여기서 O는 관측 빈도, E는 기대 빈도를 나타냅니다. 각 셀에 대해 이 계산을 수행한 후, 모든 셀에 대해 계산된 값을 더해 최종 카이제곱 통계량을 얻습니다.
제가 제공한 계산에서는 총 9개의 셀(3행 × 3열)에 대한 관측 빈도와 기대 빈도 차이를 사용하여 카이제곱 통계량을 계산했습니다. 이 값은 58.21로 나왔습니다. 이 값은 두 변수 사이의 전반적인 연관성의 정도를 수치적으로 나타냅니다.
계산된 카이제곱 통계량을 통해 우리는 가족 규모와 세탁기 크기 사이에 통계적으로 유의미한 연관이 있다는 결론을 내릴 수 있습니다. 이는 귀무 가설이 기각되었음을 의미하며, 즉 가족 규모에 따라 선호하는 세탁기의 크기가 다르다는 것을 통계적으로 입증한 것입니다.
4. 결론 도출
이 카이제곱 통계량을 자유도가 (행의 수 – 1) × (열의 수 – 1) = (3 – 1) × (3 – 1) = 4인 카이제곱 분포와 비교하여 유의수준 0.05에서의 임계값을 찾습니다. X2(0.05;4)crit = 9.49 일반적으로, 자유도가 4일 때, 유의수준 0.05의 임계값은 대략 9.49입니다.
계산된 카이제곱 통계량(58.21)이 임계값(9.49)보다 훨씬 크기 때문에, 우리는 귀무 가설을 기각하고 대립 가설을 채택합니다. 즉, 가족 규모와 세탁기의 크기 사이에는 통계적으로 유의미한 관련이 있다고 결론지을 수 있습니다. 이는 가족 규모에 따라 선호하는 세탁기의 크기가 다르다는 것을 의미합니다.
