이원분산분석 이론, 공식, 검증절차
이원분산분석(팩토리얼) 필수 체크 포인트 연구문제를 설정한다 (보통 변수 1과 변수2 간에는 상호작용 효과가 있는가? 로 시작) 가설을 설정한다 (귀무가설: 상호작용 효과 없다. 대립가설: 상호작용 효과가 있다.) 데이터를 축소한다. (각 행렬 평균값 구해야 함) (어려움) 변수1, 변수2, 상호작용(변수X변수), 오차의 제곱합을 구한다. (복잡한 계산 과정을 거침) (어려움) 각각의 제곱합을 토대로 분산분석표를 제작한다. (헷갈리기 쉬움) d.f: 변수 1의 자유도는 a-1, 변수 2의 자유도는 b-1, 상호작용 자유도는 (a-1)(b-1), 오차자유도는 n-ab 최종 F통계량들의 분모는 오차의 평균제곱이(MSE) 들어간다 F crit(a;상호작용 자유도, 오차자유도)= ? <-> F obs와 비교 후 결론 도출
이원분산분석 검증 이론
이원분산분석(ANOVA)은 두 가지 이상의 독립변수가 하나의 종속변수에 미치는 영향을 검증하기 위해 사용되는 통계적 방법입니다. 이 방법은 특히 두 개의 독립변수가 주어졌을 때, 각 독립변수의 효과뿐만 아니라 두 변수의 상호작용 효과까지도 분석할 수 있습니다. 즉, 하나의 변수가 다른 변수의 수준에 따라 어떻게 다르게 영향을 미치는지를 알아볼 수 있습니다.
이원분산분석의 주요 구성요소
- 독립변수: 연구에서 변화를 주는 변수로, 이원분산분석에서는 두 개의 독립변수를 사용합니다. 예를 들어, 식물의 성장에 미치는 영향을 연구할 때 ‘물의 양’과 ‘햇빛의 양’을 독립변수로 설정할 수 있습니다.
- 종속변수: 연구에서 측정하는 변수로, 독립변수에 의해 영향을 받는 것으로 가정됩니다. 예에서는 식물의 ‘성장률’이 될 수 있습니다.
- 상호작용 효과: 두 독립변수가 결합됐을 때 종속변수에 미치는 고유한 효과입니다. 예를 들어, 물의 양과 햇빛의 양이 식물의 성장에 미치는 상호작용 효과를 분석할 수 있습니다.
이원분산분석의 과정
- 가설 설정:
- 귀무가설(H0): 두 독립변수 모두 종속변수에 영향을 주지 않는다.
- 대립가설(H1): 적어도 한 독립변수가 종속변수에 영향을 준다.
- 데이터 수집 및 분류: 두 독립변수에 대한 다양한 수준을 결합하여 실험 그룹을 형성하고, 각 그룹에서 종속변수의 값을 측정합니다.
- 분산 분석: 데이터의 분산을 분석하여 독립변수가 종속변수에 미치는 영향과 상호작용 효과를 평가합니다. 이 과정에서는 F-통계량을 계산하여, 귀무가설을 기각할지 여부를 결정합니다.
- 결과 해석: F-통계량과 p-값을 사용하여 귀무가설을 기각할지 말지를 결정합니다. p-값이 통계적 유의수준(예: 0.05)보다 작으면 귀무가설을 기각하고, 적어도 한 독립변수가 종속변수에 유의미한 영향을 미친다고 결론 내립니다.
이원분산분석의 중요성
이원분산분석은 두 변수의 영향력과 그 상호작용을 동시에 분석할 수 있어, 실제 실험에서 변수들이 어떻게 결합하여 결과에 영향을 미치는지를 더 잘 이해할 수 있게 합니다. 예를 들어,
물과 햇빛의 양이 식물의 성장에 미치는 영향을 연구할 때, 이원분산분석을 통해 물의 양이 적당할 때 햇빛의 양이 성장률에 더 큰 영향을 미치는지, 혹은 그 반대의 경우가 있는지를 알아볼 수 있습니다. 만약 어떤 특정한 조건에서만 식물의 성장이 유의미하게 증가한다면, 그것은 두 변수의 상호작용 효과 때문일 수 있습니다.
이러한 분석을 통해, 연구자는 두 변수 각각의 독립적인 효과뿐만 아니라, 그들이 서로 어떻게 작용하며 종속변수에 영향을 미치는지에 대한 이해를 얻을 수 있습니다. 이것은 실제 응용에서 중요한 의미를 가지며, 특히 복잡한 자연 현상이나 사회 과학 연구에서 그 가치가 큽니다.
데이터 해석의 예
이원분산분석 결과를 해석할 때, 우리는 세 가지 주요 결과를 살펴봅니다:
- 주효과(Main Effects): 각 독립변수가 종속변수에 미치는 평균적인 영향입니다. 예를 들어, 실험 결과가 물의 양이 증가함에 따라 평균적으로 식물의 성장률이 증가한다면, 이는 물의 양에 대한 주효과가 있다는 것을 의미합니다.
- 상호작용 효과(Interaction Effects): 한 독립변수의 영향이 다른 독립변수의 수준에 따라 변하는 경우, 우리는 두 변수 사이에 상호작용 효과가 있다고 말합니다. 예를 들어, 물의 양과 햇빛의 양이 식물 성장에 미치는 영향이 각각 다른 수준에서 서로 다르게 나타난다면, 이는 두 변수 사이에 상호작용 효과가 있음을 의미합니다.
- 통계적 유의성(Statistical Significance): F-통계량과 p-값을 통해, 우리는 결과가 통계적으로 유의미한지를 평가합니다. p-값이 0.05 미만이면 결과가 통계적으로 유의미하다고 간주합니다. 이는 우리의 발견이 우연이 아니라 실제 효과 때문이라는 것을 의미합니다.
이원분산분석은 두 개 이상의 독립변수를 가진 실험적 또는 관찰적 연구에 널리 사용되며, 복잡한 데이터에서 패턴과 관계를 파악하는 데 중요한 도구입니다. 올바르게 수행하고 해석하면, 이 방법은 연구자가 데이터를 더 깊이 이해하고 보다 정확한 결론을 도출하는 데 도움이 됩니다.
저관여 신제품의 경우 소비자의 광고에 대한 태도는 브랜드태도에 상당한 영향을 미칠 수 있다. 신제품 광고로서 세 가지 광고대안을 개발했고 피실험자들에게 노출시킨 후 광고태도를 측정하여 소비자들이 좋아하는 광고를 선택하고자 한다. 마케터는 이러한 광고대안들에 대한 태도가 남녀간에 다를지도 모른다고 생각하고 남 녀 중에 어느 집단이 어떤 광고를 더 좋아하는지 알기를 원한다. 남녀 각 9명의 피실험자들을 6개의 cells에 할당하고, 각 피실험자들에게 세 가지 광고 중 하나를 보여주었다. 피실험자들은 광고태도를 0.0~5.0 (간격 0.1) 의 척도상에 표시하였다. 결과는 표와 같다.
연구문제 설정 (두 가지 연구문제가 도출)
광고대안들에 대한 태도는 성별에 따라 다를것인가? (a=.05)
광고대안과 성별 간에는 상호작용효과가 있는가? (a=.05)
연구문제가 “광고대안과 성별 간에 상호작용 효과가 있는가?”에 초점을 맞춘다면, 이원분산분석에서 상호작용 효과를 살펴보는 것이 중요합니다. 상호작용 효과를 분석하기 위해서는 각 조합에 대한 평균과 전체 평균, 그리고 각 조합 내의 변동을 고려해야 합니다
1단계 가설설정
H0(귀무가설) 상호작용효과가 없다.
H1(대립가설) 상호작용 효과가 있다. (남녀간에 다르다)
상호작용 효과
상호작용 효과(Interaction Effect)가 있다는 말은 두 개 이상의 독립변수(예: 성별과 광고대안)가 결합했을 때, 그들이 종속변수(예: 광고에 대한 태도)에 미치는 영향이 단순히 개별 변수의 효과를 더한 것 이상이라는 의미입니다. 즉, 한 변수의 영향이 다른 변수의 수준에 따라 달라질 수 있음을 나타냅니다.
예를 들어, 성별에 따라 어떤 광고대안이 더 효과적이라고 할 때, 단지 남성이 다른 광고보다 A 광고를 더 선호하고, 여성이 B 광고를 더 선호하는 것 이상의 의미를 가집니다. 상호작용 효과가 있다면, 남성에게는 A 광고가 효과적이지만, 여성에게는 A 광고의 효과가 남성만큼 강하지 않거나, 반대로 B 광고가 더 효과적일 수 있습니다. 다시 말해, 성별에 따라 광고대안의 효과성이 달라지며, 이는 두 변수가 서로 ‘상호작용’한다고 볼 수 있습니다.
상호작용 효과의 존재는 복잡한 현실 세계에서 두 변수 이상이 결합하여 예상치 못한 결과를 초래할 수 있음을 보여줍니다. 이를 통해 우리는 변수들 간의 관계가 단순한 합이 아닌, 더 복잡한 관계에 있다는 것을 이해할 수 있으며, 이는 연구나 실제 적용에서 변수들을 고려할 때 매우 중요한 정보를 제공합니다. 상호작용 효과의 검증은 연구 설계와 데이터 분석에서 중요한 부분을 차지하며, 특히 다변량 데이터 분석에서 필수적인 과정입니다.
2단계 분산 분석 (평균값 구하고, SS 구하기)
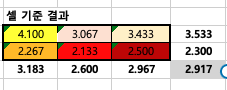
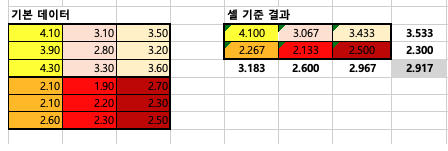
기본데이터 셀과열 평균으로 축소시키기
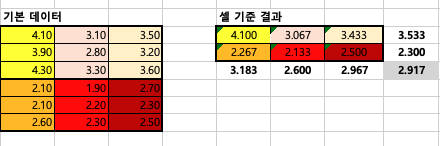
기본 데이터를 오른쪽과 같이 축소시켜줍니다. 이후 각 행렬의 평균값을 구해줍니다.
예를 들어 4.1이라는 값은 > 4.1+3.9+4.3/3 을 한 값이에요 3.067의 값은 > 3.1+2.8+3.3/3을 한 값이에요
첫 번째 변수의 제곱합 구하기 (광고) SS-A
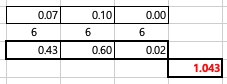
첫번째 변수의 제곱합의 경우, 각 열의 평균(3개)과 전체 평균과 편차의 제곱(각 6개씩)의 합입니다. 이유는 각 열에 자료가 6개 씩 있기 때문(2개 셀 기준)입니다.
즉 0.43 이라는 값은 첫번째 변수의 첫 열의 평균은 3.183 - 전체 평균 2.917 의 제곱 = 0.07 > X6 = 0.43 0.6이라는 값은 첫번째 변수의 두번째 열의 평균 2.6 - 전체평균 2.917 의 제곱 = 0.10 X6 = 0.6 0.02는 세번째 열의 평균인 2.967 - 2.917 의 제곱 = 0.00 X6 = 0.02 첫번째 변수의 제곱합은 0.43 + 0.6 + 0.02 = 1.043 입니다.
두번째 변수의 제곱합 구하기 (성별) SS-B
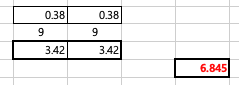
두번째 변수의 제곱합의 경우, 각 행의 평균(2개)과 전체 평균과 편차의 제곱(각 9개씩)의 합입니다. 이유는 각 행에 자료가 9개 씩 있기 때문(3개 셀 기준)이에요.
3.42라는 값은 > 두번째 변수의 첫 행의 평균값인 3.533에서 - 전체 평균 2.917 을 빼고 제곱 = 0.38 X9 = 3.42 3.42라는 값은 > 두번째 변수의 두번째 행의 평균값인 2.3에서 - 전체 평균 2.917을 빼고 제곱 = 0.38 X9 = 3.42 두번째변수의 제곱합은 3.42 + 3.42 = 6.845 입니다.
상호작용의 제곱합 구하기 SS-AB
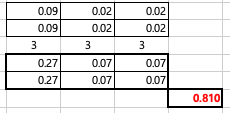
상호작용 제곱합의 경우, 해당 내용에서 변수가 두개이므로 전체 셀 평균(6개)에서 각 행과 열의 평균을 빼고 전체 평균을 더한 값의 제곱의 합 입니다. 단, 각 셀에는 3개 데이터가 존재하기 때문에 그 숫자만큼 곱한 결과를 나타내면 되어요.
0.27이라는 값: 셀 기준 결과에서 4.1 - 3.533 - 3.183 + 2.917 ^2 -> X3 (각 셀마다 데이터 수) -> 0.27 0.27이라는 값: 셀 기준 결과에서 2.267 - 2.3 - 3.183 + 2.917 ^2 -> X3 (각 셀마다 데이터 수) -> 0.27 ... 이런식으로 모두 6번 계산을 해준 후, 합하면 0.810이 나오게 됩니다. 이것이 바로 상호작용의 제곱합입니다.
오차 제곱합 구하기
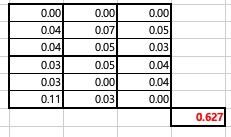
오차제곱합은 원래 기존 데이터에서, 셀 평균값을 빼고 제곱합 해주면 됩니다.
0.00 이라는 값은 > 기본데이터의 4.1에서 셀 기준 결과 4.1을 뺀 후 ^2를 해주었기 때문에 0입니다. 0.04라는 값은 > 기본데이터의 3.9에서 셀 기준 결과 4.1을 뺀 후 ^2를 해주었기 때문에 0.04입니다.. .... 이런식으로 총 18번의 계산을 해준 후 다 더하면 오차 제곱합은 0.627이 나오게 됩니다.
3 단계 분산분석표 제작하기

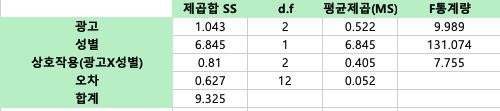
위의 두 변수의 제곱합, 상호작용 제곱합, 오차 제곱합만 구하면 나머지 값들을 도출하고 최종적으로 F통계량을 도출할 수 있습니다.
이때 첫번째 변수(광고)의 d.f는 3-1 >2
두번째 변수 (성별)의 d.f는 2-1 >1
상호작용의 d.f는 2X1 = 2
오차의 d.f는 (n-ab)이기 때문에 18 – 6 = 12입니다.
이원분산분석에서는 상호작용의 통계량으로 평가해야 합니다.
4단계 임계값 찾고 결론 도출하기
F crit = (a;상호작용 자유도, 오차자유도) 이기 때문에 F crit (0.05; 2,12)로 = 대략 3.89가 나오게 됩니다.
상호작용의 통계량 F obs는 7.755이기 때문에 임계치보다 큽니다. 따라서 귀무가설이 기각되고, 대립가설이 채택됩니다.
따라서 상호작용의 효과는 유의미하며, 광고대안들에 대한 태도는 성별에 따라 다르다고 결론이 납니다.
